京都大学大学院経済学研究科教授 依田高典氏に聞く
(2)異質介入効果と因果予測、ターゲティング
同根にある経済学と機械学習
経済学と機械学習の融合についてはいかがでしょう。
依田 計量経済学も機械学習も、もともとは統計学から派生しています。計量経済学は応用統計学そのものですし、人工知能の教科書でも統計学的な話題が半分を占めます。
それぞれ異なる方向性で発展してきたということですね。
依田 目的や方法が異なります。計量経済学の目的は、パラメーター推定と仮説検定です。サンプルから得られた仮説が母集団にどれだけ当てはまるかを重視しますから、母集団の確率分布を仮定したうえで推定・検定するパラメトリック推定という方法を使います。一方、機械学習はデータの潜在パターンを発見して予測することを目的としています。重要なのは因果関係ではなく予測誤差を最小化することなので、母集団の確率分布を仮定しないノンパラメトリック推定というアプローチをとります。パラメーターの仮定を置かないので仮説検定はできませんが、予測性能がディープラーニングによって格段に上がり、人間をしのぐようになりました。また、データの使い方も異なります。計量経済学の定理は、データ数が無限に近づけば近づくほど近似的に成り立つという漸近性に基づきますから、1 万個のデータがあれば 1 万個すべてを使って推定や検定を行います。一方、機械学習ではデータを全部使ってしまうと、そのデータのみに適応した学習が過剰に進んでしまい、未知のデータから推定する性能が落ちる「過学習」と呼ばれる事象が起こってしまいます。ですから 1 万個のデータがあれば、5,000 個を学習のために使い、残り 5,000 個を予測のテストのためにとっておくということをします。
因果推論の分野においては、過去のデータに基づいて因果関係を導き出す計量経済学と、予測はできるものの因果関係はブラックボックス化している機械学習とが相互補完するイメージですね。
依田 はい。ディープラーニングを使ってビッグデータを幾層にも畳み込んでいくと、高確率の予測ができる。ただしそれを解釈できないとなると、やはり人間としては不満が残るのだろうと思います。解釈するためには、やはり因果的な説明が必要になります。
XAI(Explainable Artificial Intelligence:説明可能な人工知能)の発想ですね。ただし、データ量やその扱い方をはじめとする経済学と機械学習とのギャップをどう埋めていくのかが気になります。
依田 経済学では、ランダムフォレスト1の手法をよく使います。決定木2予測の応用で、ランダムに分割した訓練データによって学習した多数の決定木を使って学習した結果を、最後に平均する方法です。第 2 次人工知能ブームで用いられたアルゴリズムで古典的ではあるのですが、統計学の漸近的な性質などと相性がよいですし、各プロセスで何をしているのかが見えるので使いやすいのです。決定木というのも、ゲーム理論におけるディシジョン・ツリー3としてよく使ってきた考え方でした。最後に平均することは、私たちからすると大雑把で厳密さに欠けるようにも思えたのですが、うまく予測することは間違いありませんでした。
サイエンスとして美しくなくても役に立てばよいだろうというハッカー的発想ですね。
依田 結果についてはたしかに説得性がありました。2019 年に、このランダムフォレストを因果推論に融合した「コウザルフォレスト」という手法が誕生しました。これにより、RCT(Randomized Controlled Trial:無作為比較対象実験)では平均介入効果しかわからなかったのが、個人の属性情報を利用して、一 人ひとりについて因果推論をできるようになりました。
そうすると、誰にどのような介入を行えば効果があるのかがわかるということですね。
依田 コウザルフォレストを用いて、ナッジとキャッシュ・インセンティブ(リベート)を使った節電実験を行いました。いままでの因果推論では平均的な介入効果しかわかりませんでしたが、一人ひとりの異質介入効果が識別できるようになりました。
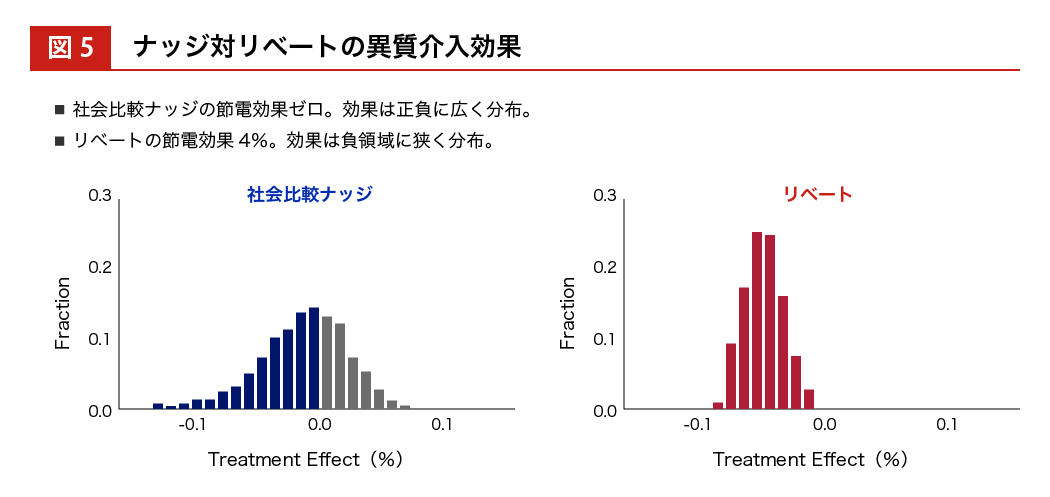
図5:ナッジ対リベートの異質介入効果
ナッジの節電効果は 0 パーセントを中心にプラスとマイナスに分布していて、リベートの場合はマイナスの方向領域に絞って効果が分布しています。また、バリアブル・インポータンスという 一つひとつの説明変数の重要性を羅列することもできます。すると、介入する前のベースラインとなる電力消費量が大きいか/小さいか、ということが効果の重要な予測因子になることもわかってきます。
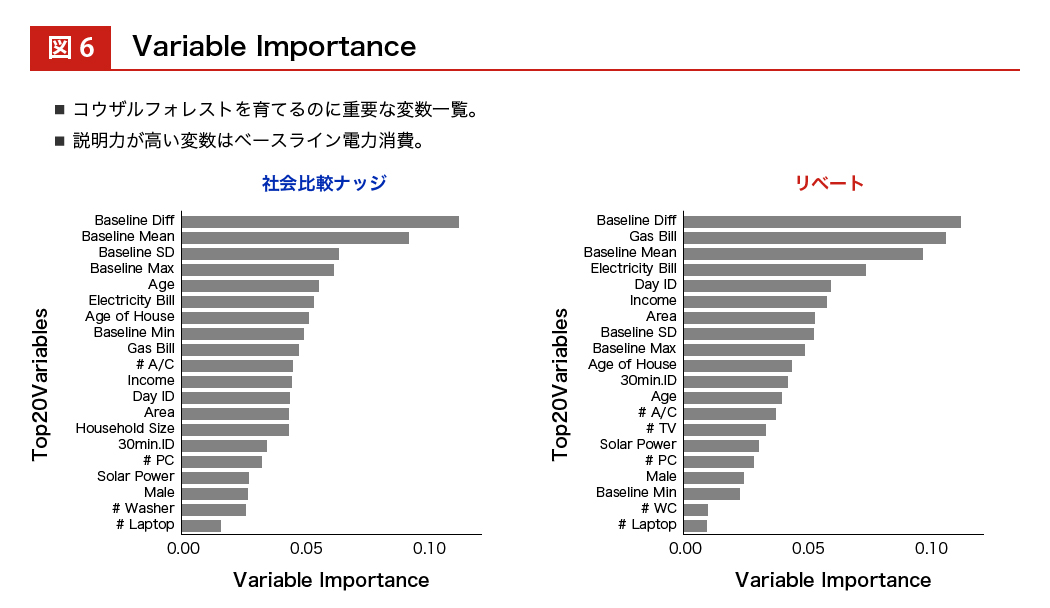
図6:Variable Importance
そうすると、ベースラインとなる電力消費量が大きいか小さいかを横軸にとって、 実際に介入効果が効いたか/効かなかったかの分布をみることができます。
電力消費量がマイナスに行くほど効果があったとことを表すので、ベースラインの電力消費量が小さい人のほうがマイナス 0.110 %に近づいていて、介入効果があったことがわかります。ここまでわかってくると、この人はナッジが効く人だ、この人はお金を与えないと行動変容しない人だということがわかり、個別にターゲティングすることができます。トータルでは 26 %の人にはナッジの方がよく効く、74 %の人にはリベートを与えた方がよく効くということがわかり、 誰に与えるべきかということも識別できるようになります。
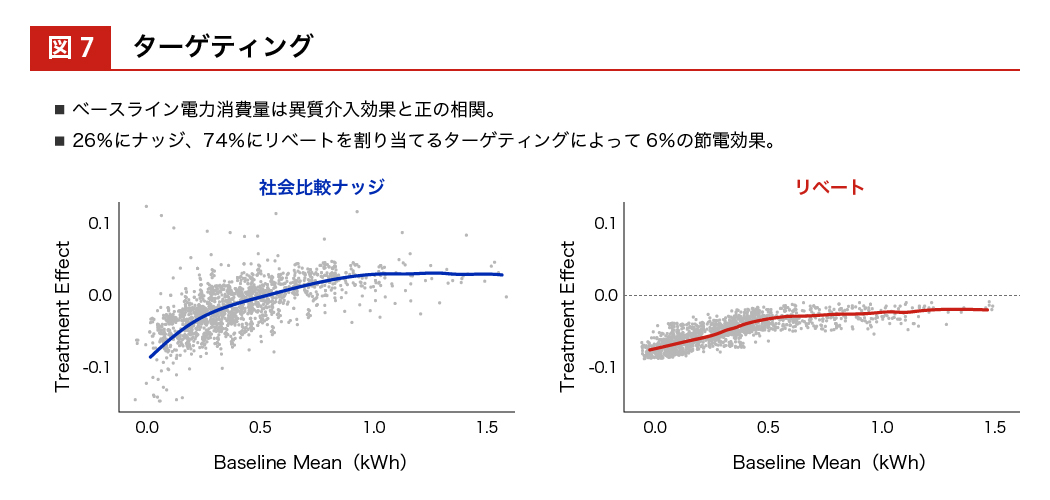
図7:ターゲティング
統計学が機械学習と計量経済学に分岐して、因果推論において融合してコウザルフォレストが誕生した。それを行動経済学とフィールド実験にあてはめると異質性がわかり、その異質性を使ってターゲティングできる、という流れですね。
依田 私たちが行っているのはポリシー・ターゲティングですが、GAFA は広告ターゲティングにおいて同じことをしています。
GAFA の持っている個人データの量は経済学者が扱う量より圧倒的に多いですよね。
依田 彼らが行っている広告ターゲティングの介入効果はそれほど強くありません。持っているビッグデータの量に比べると、わずかしか使っておらず、大きく行動を変えるというまでの介入には至っていませんね。
GAFA もAppleも、現在はヘルスケアデータやバイタルデータを集めようとしていますね。
依田 そうしたパーソナル性が高く、人の機微に触れるようなデータを用いて、健康や将来疾病リスクなどをナッジとして行動変容を促されたときに、人はどこまで抵抗できるだろうかとは思います。一方、かつてマイクロソフトが司法省と争って最先端テックの座を降りたように、プラットフォーマー規制が強くなると、GAFAもそこまでのビジネスはできなくなるかもしれません。


