東京大学ニューロインテリジェンス国際研究機構特任教授 長井志江氏に聞く
第3回 LLMでは理解できない知性の核心

知能は言語だけで、また脳だけで捉えられるものだろうか。長井氏は、心拍や呼吸など非言語的・無意識的な身体信号の処理にこそ、人間らしい知能の核心があると指摘する。インタビュー第3回では、ロボットと幼児による描画実験や、チンパンジーの先行研究を参照しつつ、予測情報処理モデルに基づく“身体化された知能”の働きを可視化する試みについて話を聞いた。

長井 志江(ながい ゆきえ)
東京大学国際高等研究所ニューロインテリジェンス国際研究機構特任教授。博士(工学)。構成的アプローチから人間の社会的認知機能の発達原理を探る認知発達ロボティクス研究に従事。自他認知や模倣、他者の意図・情動推定、利他的行動などの認知機能が環境との相互作用を通した感覚・運動信号の予測学習に基づき発達するという仮説を提唱し、計算論的神経回路モデルの設計とそれを実装したロボットの実験によって評価。さらに自閉スペクトラム症(ASD)などの発達障害者のための自己理解支援システムを開発。ASD 視覚体験シミュレータは発達障害者の未知の世界を解明するものとして高い注目を集める。Analytics Insight “World’s 50 Most Renowned Women in Robotics”(2020)、IEEE IROS “35 Women in Robotics Engineering and Science”(2022)、Forbes JAPAN “Women In Tech 30”(2024)などに選出。2016 年より CREST「認知ミラーリング」、2021 年より CREST「認知フィーリング」の研究代表者。
目次
LLMだけでは知能を理解できない
都築 正明(以下――)先生のお話を伺うと、言語ベースのLLM(Large Language Model:大規模言語モデル)では、頭でっかちなものしか理解できないように思えます。
長井 身体性を持たないことが、知能を理解するうえで本質的な部分を欠いてしまうのではないかと考えます。ChatGPTのように言語を使ってやり取りするだけでは、知能の本質を理解するのは難しいのではないでしょうか。私たちは、言語に現れないところで多くの情報処理をしているはずですから、その情報処理を支える身体性を備えたシステムとして研究しなければ、言語化されていない知能を捉えることができません。その一例として、心拍や呼吸といった内受容感覚が挙げられます。内受容感覚は無意識レベルで処理されますが、私たちの行動決定において重要な役割を果たしています。同様のことが、コミュニケーションにも見られます。私たちは誰かと話をする際にアイコンタクトをしますが、いつどの程度、相手の目を見るべきかについて、明確なルールがあるわけではありません。言語化されにくい情報処理の過程にも、重要な意味があると思います。興味深いことに、アイコンタクトが苦手な発達障害の方も、ルールベースで学習をすれば、相手に視線を向けるようになります。
必要ではないけれど、儀礼的関心の手続きとして行うわけですね。
長井 そうなんです。言語で記述されれば、それを学習することができる。一方で、言語化されにくいことは、学習も難しい。人間の知能には言語化されていない部分がたくさんあり、それらが身体性に基づく経験を通じてどのように獲得されるかを理解することが、知能の本質的解明のために重要なのだと思います。内受容感覚についても、ChatGPTに「心拍とはなんですか」「呼吸とはなんですか」というように言語で聞けば、言語で回答してくれます。それは人が辞書などのテキストに書きだした原典があるからです。だからと言って、ChatGPTが心拍や呼吸に基づいて環境認識したり行動決定しているわけではありません。
研究者によっては、言語には身体性もシンボライズされていると考える方もいらっしゃいますし、すべてを写像する世界モデルを構築しようとする方もいらっしゃいます。
長井 言語で構成されているかぎり、LLMのようなAIは、言語化できない感覚運動情報を処理することができません。身体性を持ったAIモデルを作ることで、言語では表現できない身体に根付いた情報処理の重要性が、はじめて見えてくると思います。
描画実験が示唆する発達と個性の発現プロセス
そこで、先生はロボットを利用してシミュレーションを行っているのですね。
長井 私の研究室で行っている研究の一例に、お絵描きの実験があります。ロボットと並行して、人のお子さんでも同じ実験をしています。ロボットはあらかじめ、いくつかの描画パターンを学習しており、絵の一部が呈示されると、学習したパターンにもっとも近いパターンを推論して、足りない特徴を描き足します。人の場合も、絵の一部だけを見ると描き足したいというモチベーションが出てきます。私は、それがまさに予測誤差の最小化だと思っています。円を見たときに顔をイメージすると、自分が考える顔のパターンと、いま見える単なる円とのあいだに誤差が発生します。すると、誤差を減少させるように、円の内側に目や口などの顔の特徴を描いてしまいます。これをiCubというロボットで比較したのが以下の実験です。

左が定型発達のようなモデル、右は発達障害まではいきませんが、未熟で予測が弱く感覚に鋭敏なモデルを用いています。結果は以下のようになりました

結果:感覚・予測信号の精度の変調による多様な描画(長井先生提供)
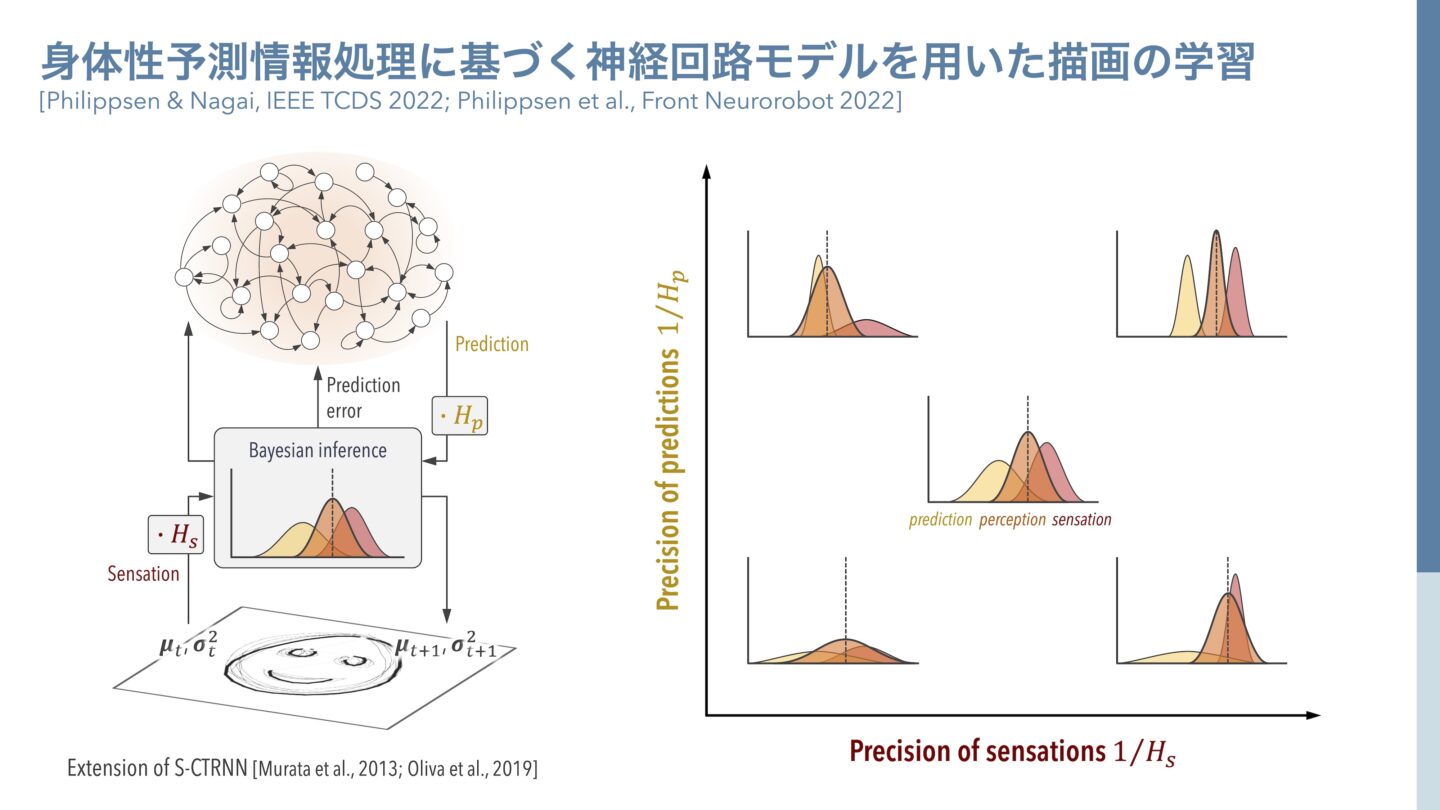
身体性予測情報処理に基づく神経回路モデルを用いた描画の学習(長井先生提供)
長井 並行して、人のお子さんに同じ課題を与えた実験も行いました。ここでもロボット実験と同様に、タブレット上に絵の一部だけを表示して、お子さんには好きなものを描いてもらいました。

結果:子供の描画能力の発達と多様性(長井先生提供)
長井 右上の99か月のお子さんは比較的年齢が高いので、呈示されているものが目と鼻と口だと思うと、顔の輪郭を描き出してくれます。一方で、左下の27か月のお子さんは年齢が低いので、顔の輪郭をみても何をしてよいのかわからず殴り描きをしてしまいます。このようにみていくと、低年齢のお子さんは殴り描きが多く、年齢が高くなると足りない特徴を描き足すということが現れることがわかりました。さらに面白いのは多様性のパターンです。右側の上から2番目(70months)と上段の真ん中(59months)では顔のパーツをランダムに配置しているので、直観的に顔っぽいなと思いつつ、目の位置がずれているので顔を描きづらくて逡巡した様子がみられます。上段の真ん中(59months)と右側(99months)、それに左側の上から2番目(46months)では、家のパーツをバラバラに配置しました。右上の99か月のお子さんはクリエイティブで、家を2階建てにして2階のドアまで階段をつけていて私たちも驚きました。このお子さんは、おそらく2階建ての家を見たことがあって、そのモデルを持っているからこそ描き足すことができて、階段がないと家に入れないと理解をしているのだと考えられます。イメージを描き写すのではなく内部モデルとして持っているからこそ、このような予測ができて、予測誤差を最小化するような行動が出てきたのだろうと考えられます。
2階のドアへの階段を描いたお子さんは、ドアに至るまでの行動のスキームが予測できているようにも考えられますね。
長井 中央の散布図は、実際に104名のお子さんからデータを取ってプロットした結果です。左下には赤いデータ点で殴り描きの例(27months・41months・38months)を示していますが、不規則な殴り描きもあれば規則的な殴り描きもあって、個性がみられます。右上にいくに従って、だれがみても家や車だとわかるようなパターンが出てきます。左下から右上に向かって、発達の変化が現れることが見て取れます。また点の色で、お絵描きの種類をカテゴライズしています。ここにも個性が現れていて、青いデータポイントのお子さんは、呈示された黒い線とお子さんが描いた青い線がほぼ重なっていて、なぞり描きをしています。車のパーツがあっても、ボディを描かずにひたすらなぞっています。これらのお子さんと、紫で示したお子さんとを比較すると、紫で示したお子さんは丸・バツ・三角のような幾何学模様を描いています。ここには例示していませんが、お花をひたすら描くお子さんもいて、それらを比較すると、見えている線に強く引きつけられるお子さんと、逆に線をほぼ無視するお子さんとの両極端がいて、それが個性として現れることがわかってきました。それが、予測情報処理でいうボトムアップで視覚に入ってくる感覚信号に引きつけられて描くか、脳内からのトップダウンな予測信号に基づいて描くかという違いであると考えられます。丸・バツ・三角やお花をひたすら描くお子さんは、見えているものにかかわらず、自分の脳からつくりだしたパターンに引きつけられているのでしょう。トップダウンの信号が強くはたらくか、ボトムアップからの信号が強くはたらくかの傾向により、個性が発現するということです。
そうした個性が現れることはコンピュータ・シミュレーションやアルゴリズムを使って、計算論的に検証できるのでしょうか。
長井 ニューラルネットワークモデルを使って、トップダウンの予測信号とボトムアップの感覚信号とのバランスを変えるパラメータを導入して、ロボットを用いた実験をしました。
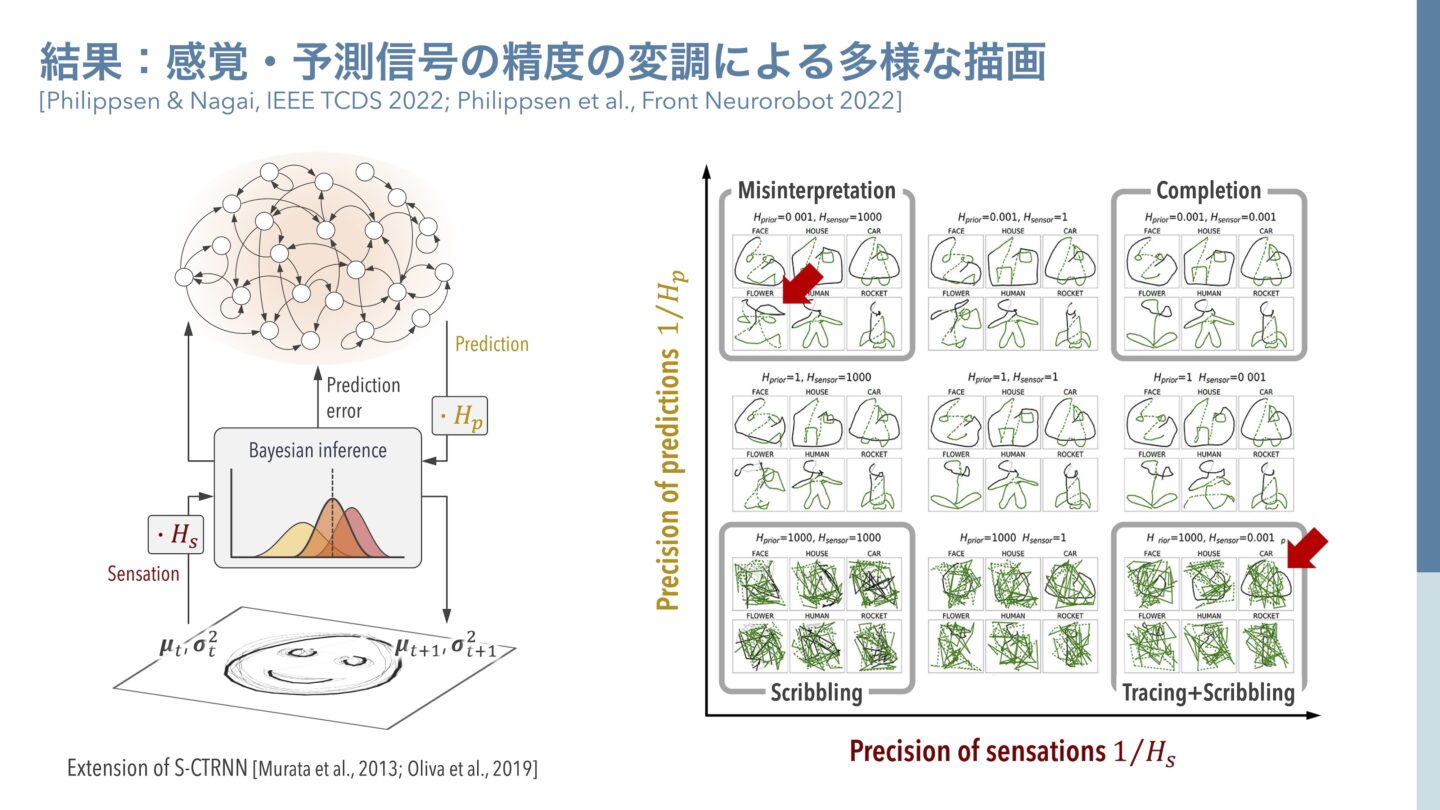
感覚・予測信号の精度の変調による多様な描画(長井先生提供)
長井 感覚信号の精度である赤く示した分布の精度を高くすると、感覚信号により強く依存するようになります。逆に、黄色で示したトップダウンの予測信号の精度を高くすると、予測信号に依存するようになります。感覚依存か予測依存かというどちらに引き寄せられているかが、オレンジで示した知覚の分布です。実際にモデルを学習させたロボットに描画をさせると、私たちが期待した通り、感覚と予測の双方が未熟な場合は左下(Scribbling)のような殴り描きになり、双方がバランスよく統合されれば右上(Completion)のような補完描画のパターンがみられました。また感覚信号への依存が強いと、右下(Tracing+Scribbling)のように、与えられた輪郭をなぞることはできて、それ以外は殴り描きになることがわかりました。これは、見たままを再現することはできるものの、新しいパターンに汎化1することができないことを示しています。反対に、予測信号に強く依存して学習させると、左上(Misinterpretation)のようにネットワークのダイナミクスの影響が強くなりすぎ、感覚信号をうまく分離できない描画が現れました。先ほどの例でいうと、自分の思い込みが激しく丸・バツ・三角や、お花ばかりを描くお子さんに近いのだと考えることができます。予測情報処理の観点から、人の発達における時間的な変化と個人差とを統一して説明できるという意味で、とても面白い実験だと思っています。
予測の世界と“今・ここ”の世界
人間は肥大した大脳前頭葉で予測を行い、その他の動物は身体感覚で環境に適応しているようにも思えます。
長井 京都大学の霊長類研究所が、子どものチンパンジー16頭と大人チンパンジー32頭を対象に同じ実験をしています。

描画能力の進化的差異:ヒト vs. チンパンジー(長井先生提供)
長井 この実験では、あらかじめグレーの線画が印刷された紙を前に、チンパンジーがペンを持って相対します。左側の黒い線が、チンパンジーまたは人のお子さんが描き足した線です。上段の図をみると、人のお子さん(Human Girl 2y2m)もチンパンジー(Chimpanzee Popo)も、描かれている目の部分をなぞっています。下段の輪郭線をなぞる描画も、人のお子さん(Human Girl 2y8m)とチンパンジー(Chimpanzee Pan)の双方に出てきます。中段の、見えないものを予測して描くことは、人のお子さん(Human Girl 2y5m)にはみられましたが、チンパンジーにはみられず空白になっています。それぞれの描画能力が何歳から発現したのかを示したのが、真ん中のグラフです。チンパンジーにはみられなかった予測して描き足す行為が、人の場合いつ頃でてきたのかをみると、1歳10か月から3歳1か月までのあいだに発達することがわかります。ここから、チンパンジーと人の能力の違いは、予測をしたり予測誤差を埋めようとするところにあるのではないかと考えられます。当時の京都大学霊長類研究所所長の松沢哲郎先生は、よくチンパンジーは“今・ここ”を生きているとおっしゃっていました。
時間の認知が違うのかもしれませんね。
長井 将来や過去といった時系列や、プレディクション(予測)能力が人とは異なるのかもしれません。いま見えているものの短期記憶でいうと、チンパンジーのほうが高い能力を持っていることもあります。有名なのは、松沢先生の考案された記憶テスト(「京都大学のチンパンジーと記憶力勝負 | 脳トリック))です。ディスプレイ上にいくつかの数字が一瞬表示されて隠され、1、2、3……とタッチして当てていくのですが、人間は1、2ぐらいまでしか覚えていられないのに、チンパンジーは写真で記憶しているかのようにすごく正確に覚えられます。見たままをフォトグラフィック・メモリー1として記憶していて、抽象化のプロセスが一切ないというのが、チンパンジーの記憶だと考えられます。安易な比較は慎むべきですが、発達障害のある方のなかには、サヴァン症候群2のように辞書や電話番号をすべて記憶できる方がいます。記憶のシステムとしては近いものがあるのかもしれません。
マイケル・トマセロ3は、チンパンジーも意図を汲むことができると主張しています。
長井 マックス・プランク進化人類学研究所では、人がなにかに手を伸ばして取れない仕草をすると、チンパンジーの子どもが取って手渡してくれるという報告がされています。なにかを取ろうとする人の行動の意図を推察して取ってあげるという意味では、意図の共有ができるという意味でのプレディクションの一種だと思います。ただ、なにかに向かって手を伸ばしているというシーンに基づいて行動しているとも考えられますし、ものを取るという見えないアクションを推定しているのかもしれません。いずれにせよチンパンジーが全くプレディクションができないわけではないとは思います。状況やタスクのデザイン、また研究所にいるチンパンジーなのか、野生のチンパンジーなのかによっても違いがあるかもしれませんね。これまで紹介した多くの実験結果からは、やはり予測という能力に違いがあるということが、みえてきます。


