異質介入効果と因果予測、ターゲティング
――京都大学大学院経済学研究科教授 依田高典氏に聞く(2)

行動経済学とフィールド実験により、経済学は現実の生活世界に基づく研究ができるようになった。ここでは、依田氏の実施した節電行動の大規模フィールド実験を参照しつつ、デジタル化された社会がもたらす私たち自身の倫理的課題について話を聞いた。私たちが持たなければならない強さと価値判断のモードとは?
取材:2023年1月26日 オンラインにて
 |
依田 高典(いだ たかのり) 京都大学大学院経済学研究科研究科長・教授 1965 年新潟県生まれ。1989 年京都大学経済学部卒、1995 年京都大学大学院経済学研究科博士課程修了。博士(経済学)。現在、京都大学大学院経済学研究科教授。同研究科長(2021 〜 2023 年度)。その間、イリノイ大学、ケンブリッジ大学、カリフォルニア大学客員研究員を歴任。専門は応用経済学。情報通信経済学、行動経済学の研究を経て、現在はフィールド実験とビッグデータ経済学の融合に取り組む。主な著書に『Broadband Economics: Lessons from Japan』(Routledge)、『スマートグリッド・エコノミクス』(有斐閣、共著)、『ブロードバンド・エコノミクス』(日本経済新聞出版社)、『行動経済学』(中公新書)、『「ココロ」の経済学』(ちくま新書)などがある。日本学術振興会賞、日本行動経済学会ヤフー論文賞、日本応用経済学会学会賞、大川財団出版賞、ドコモモバイルサイエンス奨励賞などを受賞。 |
目次
行動経済学とフィールド実験、そして機械学習の融合
――2012 年に先生が行われた節電行動の大規模フィールド実験は、社会的意義も大きいですね。
依田 私たち一人ひとりのアナログな行動が数値化されて、クラウドやオンラインの世界にアップデートされてデジタル的に観察できる“スマート革命 ”があったからこそ可能でした。これまで、月に 1 回検針員が訪問して月ごとの電力量を把握していたかわりに、各戸にスマートメーターを設置し、HEMS(Home Energy Management System:家庭内の電気使用量をコントロールするシステム)により電力消費が逐次観察できるようになったことで、エビデンスベースの行動経済学が実験できるようになったんです。
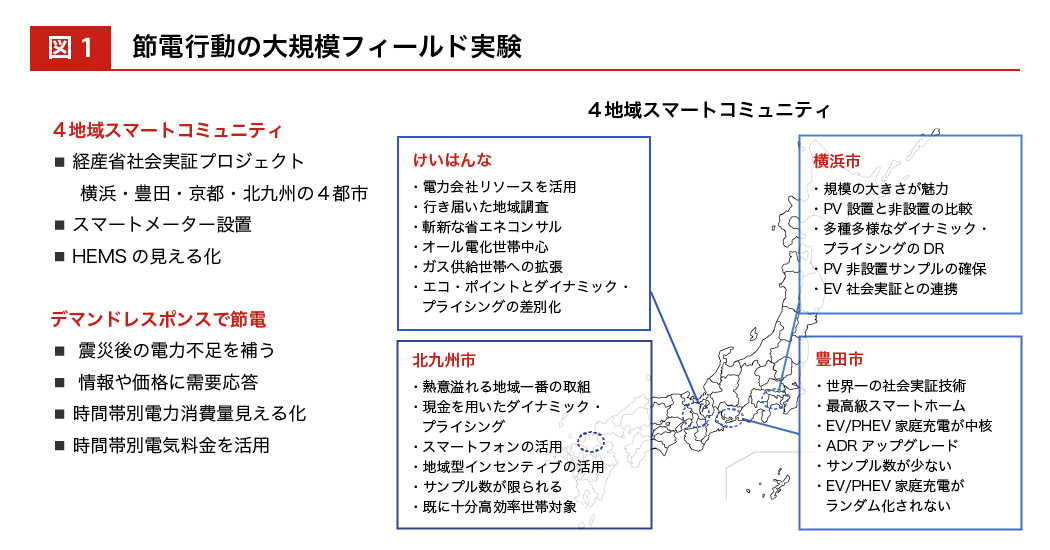
――どのような介入を行ったのですか。
依田 たとえば、けいはんな学研都市*1の場合は、世帯をランダムに 3 つのグループに割り当てました。まず 1 つめのグループは、なんの介入もしないコントロール群です。2 つめのグループには節電要請のメッセージを送って、各家庭での自律的な節電を誘導するトリートメント群にしました。3 つめのグループには、電力の消費量が増えるピーク時と、そうでないオフピーク時とで異なる電気料金を設定するダイナミック・プライシング*2のトリートメント群にしました。
*1けいはんな学研都市 正式名称「関西文化学術研究都市」は、京都、大阪、奈良の3府県にまたがる丘陵において、建設・整備を進めているサイエンスシティ。「つくば研究学園都市」とともに国家的プロジェクトに位置づけられている。
*2ダイナミック・プライシング 需要と共有のバランスを最適化して価格を変動する仕組み。
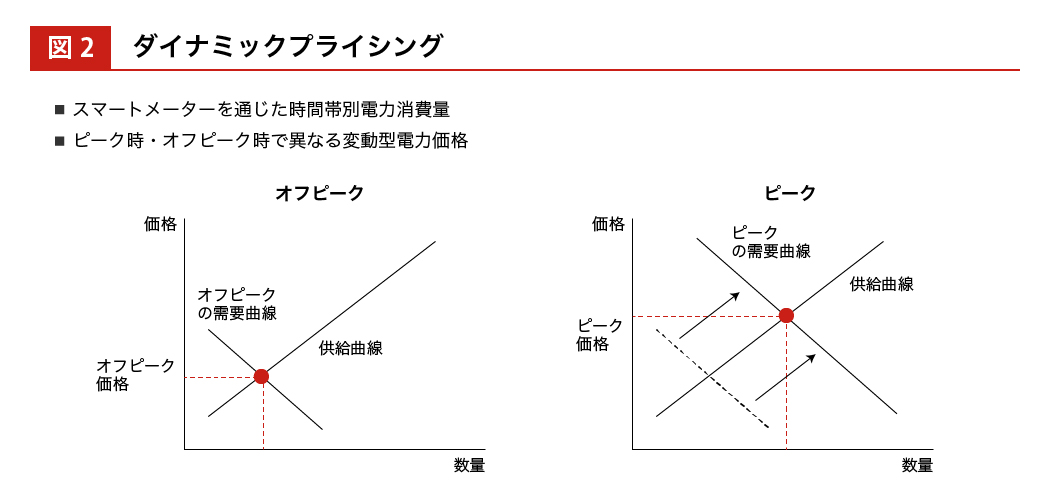

―― 節電要請については“気づき”によるナッジを、ダイナミック・プライシングでは時間帯による均衡価格の差を用いたインセンティブを用いたわけですね。
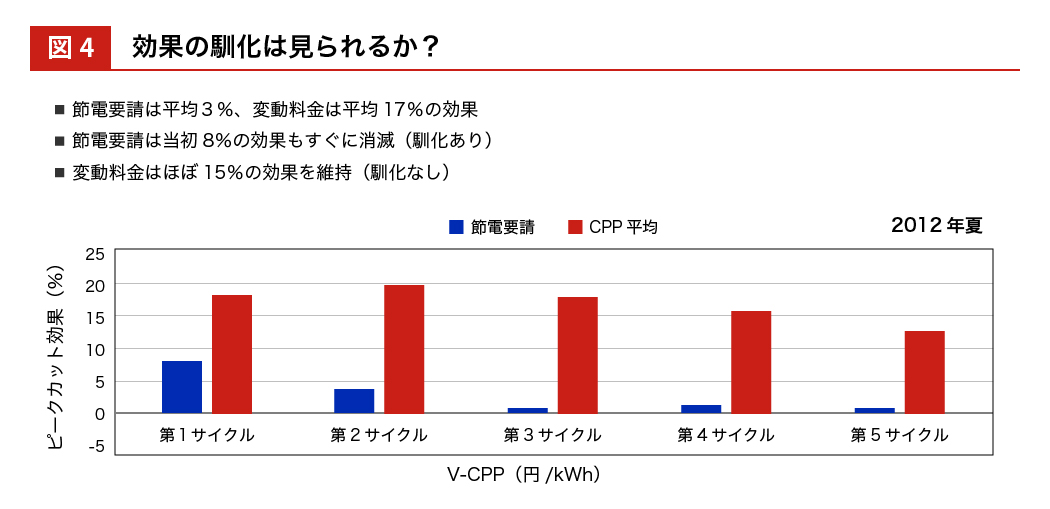
依田 実験結果は下図のようになります。横軸にある各サイクルの青いほうが節電要請で、最初の 3 日間についてはそれなりに効果があるけれど、4 日目以降はすぐに効果がなくなり、節電効果の平均は 3 パーセントに留まりました。ダイナミック・プライシングを使って、価格によって節電を誘導したのが右側の赤い柱で、平均 17パーセントの効果がみられました。回数を重ねるたびに効果が減衰する馴化もさほど大きくなく、最後まで統計的優位がみられました。このように、行動経済学とフィールド実験とが融合して机上ではなく実地で人々の行動を科学的に検証できるようになりました。
同根にある経済学と機械学習
――経済学と機械学習の融合についてはいかがでしょう。
依田 計量経済学も機械学習も、もともとは統計学から派生しています。計量経済学は応用統計学そのものですし、人工知能の教科書でも統計学的な話題が半分を占めます。
――それぞれ異なる方向性で発展してきたということですね。
依田 目的や方法が異なります。計量経済学の目的は、パラメーター推定と仮説検定です。サンプルから得られた仮説が母集団にどれだけ当てはまるかを重視しますから、母集団の確率分布を仮定したうえで推定・検定するパラメトリック推定という方法を使います。一方、機械学習はデータの潜在パターンを発見して予測することを目的としています。重要なのは因果関係ではなく予測誤差を最小化することなので、母集団の確率分布を仮定しないノンパラメトリック推定というアプローチをとります。パラメーターの仮定を置かないので仮説検定はできませんが、予測性能がディープラーニングによって格段に上がり、人間をしのぐようになりました。また、データの使い方も異なります。計量経済学の定理は、データ数が無限に近づけば近づくほど近似的に成り立つという漸近性に基づきますから、1 万個のデータがあれば 1 万個すべてを使って推定や検定を行います。一方、機械学習ではデータを全部使ってしまうと、そのデータのみに適応した学習が過剰に進んでしまい、未知のデータから推定する性能が落ちる「過学習」と呼ばれる事象が起こってしまいます。ですから 1 万個のデータがあれば、5,000 個を学習のために使い、残り 5,000 個を予測のテストのためにとっておくということをします。
――因果推論の分野においては、過去のデータに基づいて因果関係を導き出す計量経済学と、予測はできるものの因果関係はブラックボックス化している機械学習とが相互補完するイメージですね。
依田 はい。ディープラーニングを使ってビッグデータを幾層にも畳み込んでいくと、高確率の予測ができる。ただしそれを解釈できないとなると、やはり人間としては不満が残るのだろうと思います。解釈するためには、やはり因果的な説明が必要になります。
―― XAI(Explainable Artificial Intelligence:説明可能な人工知能)の発想ですね。ただし、データ量やその扱い方をはじめとする経済学と機械学習とのギャップをどう埋めていくのかが気になります。
依田 経済学では、ランダムフォレスト*3の手法をよく使います。決定木*4予測の応用で、ランダムに分割した訓練データによって学習した多数の決定木を使って学習した結果を、最後に平均する方法です。第 2 次人工知能ブームで用いられたアルゴリズムで古典的ではあるのですが、統計学の漸近的な性質などと相性がよいですし、各プロセスで何をしているのかが見えるので使いやすいのです。決定木というのも、ゲーム理論におけるディシジョン・ツリー*5としてよく使ってきた考え方でした。最後に平均することは、私たちからすると大雑把で厳密さに欠けるようにも思えたのですが、うまく予測することは間違いありませんでした。
*3ランダムフォレスト 複数の決定木に予測を行わせて、平均や多数決となるアウトプットを得る機械学習のためのアルゴリズム。
*4決定木 決定を行うためにツリー状の構造によって予測を行うグラフ。
*5ディシジョン・ツリー 決定にいたるまでのあらゆる選択肢をツリー状に構成し、最適の決定をみつける分析方法。決定木分析ともいう。
――サイエンスとして美しくなくても役に立てばよいだろうというハッカー的発想ですね。
依田 結果についてはたしかに説得性がありました。2019 年に、このランダムフォレストを因果推論に融合した「コウザルフォレスト」という手法が誕生しました。これにより、RCT(Randomized Controlled Trial:無作為比較対象実験)では平均介入効果しかわからなかったのが、個人の属性情報を利用して、一 人ひとりについて因果推論をできるようになりました。
――そうすると、誰にどのような介入を行えば効果があるのかがわかるということですね。
依田 コウザルフォレストを用いて、ナッジとキャッシュ・インセンティブ(リベート)を使った節電実験を行いました。いままでの因果推論では平均的な介入効果しかわかりませんでしたが、一人ひとりの異質介入効果が識別できるようになりました。
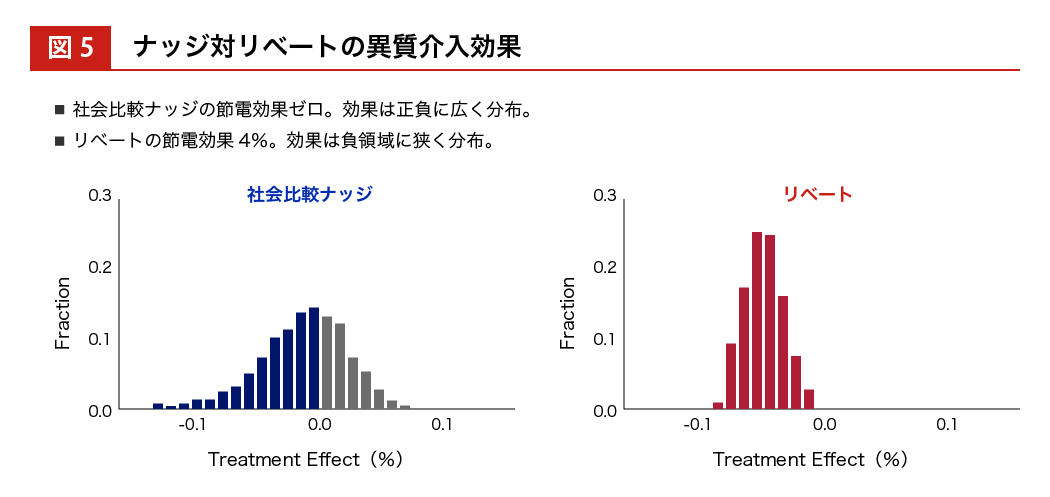
ナッジの節電効果は 0 パーセントを中心にプラスとマイナスに分布していて、リベートの場合はマイナスの方向領域に絞って効果が分布しています。また、バリアブル・インポータンスという 一つひとつの説明変数の重要性を羅列することもできます。すると、介入する前のベースラインとなる電力消費量が大きいか/小さいか、ということが効果の重要な予測因子になることもわかってきます。
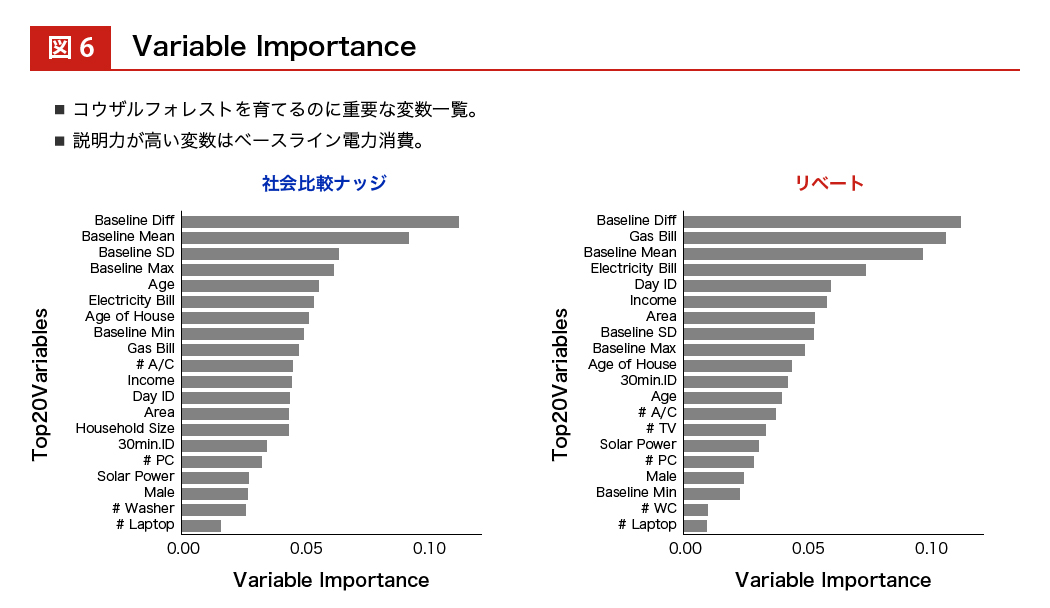
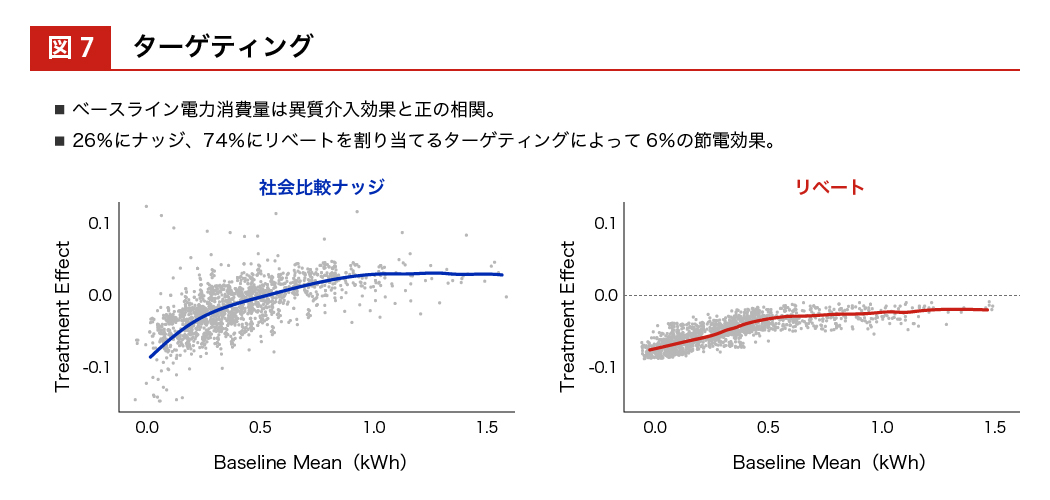
そうすると、ベースラインとなる電力消費量が大きいか小さいかを横軸にとって、 実際に介入効果が効いたか/効かなかったかの分布をみることができます。
電力消費量がマイナスに行くほど効果があったとことを表すので、ベースラインの電力消費量が小さい人のほうがマイナス 0.110 %に近づいていて、介入効果があったことがわかります。ここまでわかってくると、この人はナッジが効く人だ、この人はお金を与えないと行動変容しない人だということがわかり、個別にターゲティングすることができます。トータルでは 26 %の人にはナッジの方がよく効く、74 %の人にはリベートを与えた方がよく効くということがわかり、 誰に与えるべきかということも識別できるようになります。
――統計学が機械学習と計量経済学に分岐して、因果推論において融合してコウザルフォレストが誕生した。それを行動経済学とフィールド実験にあてはめると異質性がわかり、その異質性を使ってターゲティングできる、という流れですね。
依田 私たちが行っているのはポリシー・ターゲティングですが、GAFA は広告ターゲティングにおいて同じことをしています。
―― GAFA の持っている個人データの量は経済学者が扱う量より圧倒的に多いですよね。
依田 彼らが行っている広告ターゲティングの介入効果はそれほど強くありません。持っているビッグデータの量に比べると、わずかしか使っておらず、大きく行動を変えるというまでの介入には至っていませんね。
―― GAFA もAppleも、現在はヘルスケアデータやバイタルデータを集めようとしていますね。
依田 そうしたパーソナル性が高く、人の機微に触れるようなデータを用いて、健康や将来疾病リスクなどをナッジとして行動変容を促されたときに、人はどこまで抵抗できるだろうかとは思います。一方、かつてマイクロソフトが司法省と争って最先端テックの座を降りたように、プラットフォーマー規制が強くなると、GAFAもそこまでのビジネスはできなくなるかもしれません。
“強いシンギュラリティ”と“弱いシンギュラリティ”
――ポリシー・ターゲティングにおいては、倫理的な側面も大きいと思います。
依田 はい。悪意を持って利用すれば、人の行動をよくない方向に変容させることが可能になってしまいます。
――リチャード・セイラーとキャス・サンスティーンの提唱する「リバタリアン・パターナリズム*6」のパターナルな主体の意図にも両義性があるように思います。言葉遊びではありませんが、善導としてのナッジも、煽動としてのナッジも……。
*6リバタリアン・パターナリズム リバタリアン(自由放任)とパターナリズム(温情主義)を合わせた言葉で、選択を個々の自由に委ねつつも、過誤や偏見に陥らないよう見守って、より良い選択へ誘導する考え方。
依田 大いにありえると思います。
――権威主義国家が国民をコントロールしようとすれば、そこにも相性がよさそうです。さらにいえばディープフェイクのようなリアルな偽造技術を用いて仮想の指導者を置いたりですとか。
依田 ジョージ・オーウェルの『1984』のビッグブラザーのような世界観で、テレスクリーンで国民を監視する効率的な国家を構想することはできます。思想教育や異分子の摘発にも使えますし。人間の無意識やバイアスなども含んだデータを畳み込んで出力されるのが現在の AI の機能ですから、そこに人間の自然知能が頼るようになってしまうと負の連鎖になりかねません。たとえば独裁者が不信の中で側近を更迭していって、相談相手がいなくなったときに、AI に相談するようなことは、ありえそうな話です。アメリカ大統領選挙における SNS 利用などが典型ですが、いまでもそれに近いことは行われていますから。
――SNS上のボットに加えて、偏見や誤解を流布して大衆を扇動するような チャットボットをつくることも可能ですね。
依田 逆にいえば、人工知能からネットを介して私たちの自然知能へのフィードバックが行われているということになります。そこで私たちの価値観が変わってくると、それをまた訓練データとして人工知能のほうが学んでいくというサイクルです。そうすると、自然知能と人工知能の見分けがつかなくなり、人工知能の出力を勝手にみんなが信用しだすという事態が生じます。GPT-3*7を使ってレポートを書かせてそれを丸写しするように、自然知能が人工知能に依存するようになると、私たちの悟性が劣化する可能性はあります。
*7GPT-3 OpenAI社の高性能な言語モデル。同技術を利用した対話型モデル「ChatGPT」はその自然な文章作成の能力から大いに話題をさらっている。
――カタール・ワールドカップの日本対スペインの試合における “三苫の1 ミリ”では、VAR(Video Assistant Referee) で確認された判定が、結果として勝敗を分けることとなりました。テクノロジーへの信頼が高まることで、相対的に人間のそれを上回るということも危惧されます。
依田 私はシンギュラリティーには 2 種類あると思っています。人間より優れた知能として、人間の脅威になるような汎用型 AI が誕生する“強いシンギュラリティ”が、現在の第 3 次人工知能ブームの流れで訪れることはないと思います。ニューラルネットワークというのは、人間の脳を模しているといっても、密度としては粗く人間の脳機能には及びません。人間の意識がどう定義されるのか、またどのように生成するのかはまだわかりませんから、一人ひとりの価値観を機械で再現するというのは遠い先にあります。ただし、自然知能と人工知能とが人間側から見て区別がつかなくなる“弱いシンギュラリティ”は近いうちに訪れると思います。
――まずは“弱いシンギュラリティ”に、私たちがどう対処するかということになりますね。
依田 私たちの研究でも、どんな目的関数を考えて社会的厚生関数*8をどう最大化するかというのは人間が考えることで、それを入力してはじめてアルゴリズムが動きだします。何に価値を置いて、何を上位に持ってくるのかは、私たち人間が介入することですし、だからこそ倫理が問われるのだと思います。
*8社会的厚生関数 社会全体の資源配分の効率性、すなわち社会全体の経済的構成を評価する際の関数。
――倫理を AI に組み込む試みもありますが、価値判断をして手を動かすのは人間ですものね。
依田 経済学者のなかには、経済学は機械学習の植民地になるのではないかと懸念する人もいます。しかし AI には倫理的価値判断ができません。分配公平性や機会平等についての配慮については、やはり人間が判断する必要があります。こうした政策研究については、日本の経済学者も多くの研究成果をあげています。




