アルゴリズムを批評するために(2)

目次 アルゴリズムを批評するために(2)
入力前の不透明性 vs 入力後の不透明性
知識集約のメカニズムとして、我々は透明性を第一に考えることが多いが、透明な集約アルゴリズムをつくることが、望ましいアルゴリズムをつくることになるとは限らない。
代表的なのは、amazonのレビューのスコアだ。amazonレビューのスコアは、基本的にレビューをした人々のそのまま算術平均の点数が割り算されて表示される。どの点数がどのように足し合わされたのかは、極めて明確で、小学校の算数で理解可能な範囲である。得点表示の透明性という点では非常にわかりやすい仕組みであるといえる。透明であると同時に、理解可能な仕組みである。
だが、現在、この方式はさまざまな欠点があることもわかってきている。
第一に、サクラによるなりすましに弱い。関係者がこっそりと高い点をつけようと思えば、かなり簡単に点数をつけることができる。
第二に、SNSの炎上やバズといったものに対しても脆弱である。一度、炎上してしまえば低い点数が、一挙に付いてしまうことになる。炎上したときにほとんど誤解としか言いようがないような情報がでまわっていても、これを一つ一つ正してまわることは非常に手間がかかる。
amazonレビューのような仕組みは、点数の計算の仕組みは透明だったとしても、点数の投稿に至るまでのプロセスの不透明性に対して脆弱な構造なのだと言っていい。
こういった決定に対して、頑健性が高いのは食べログの得点のような透明性の低いスコアリングの仕組みである。食べログのスコアリングは基本的に透明性の高い統計的スコアとして表示しようという理念にはなっておらず、飲食店選びをするためのデータマイニングをしてくれるサイトだという割り切りがある。
食べログのスコアにはいくつかの特徴があるが、その一つの特徴は、初めて書き込んだユーザーの投稿点数をほぼ反映しないようになっているという仕組みが実装されているという点である。食べログを普段から使っていないユーザーが、炎上時にどれだけ沢山ネガティブなレビューをしたとしても、飲食店の点数が簡単に下がることはない。
また、10件程度のレビューが集まらないうちは食べログのスコア自体が算出されない仕組みになっている。このため、1人や2人のサクラが食べログのスコアを操作しようとしても、簡単には点数が動かない。
炎上やサクラに対する頑健性を担保するためのアルゴリズムが何重にも施されているのが、食べログのスコアの仕組みである。投稿された情報それ自体がサンプリング・バイアスの塊であるということを前提にしたデータマイニングである。これは、取得されたサンプルの情報が無作為抽出のようなバイアスのないデータであることを前提とするような統計調査的な方法論とは根底からして発想が違っている。
Amazonが入力される時点でのサンプリングの不透明性を許容しつつ、入力された後の処理を透明にしているのに対して、食べログはサンプリングされた情報の不透明性に対応するために入力された後の情報処理を不透明にしているのである。
もちろん、入力後の処理を不透明にすることによる問題はある。食べログのスコアをめぐっては、食べログ運営側による不正な操作を疑う声がたびたびあがり、食べログ側はその疑義に対して、潔白であることを証明できないという状況が続いている。有用なプラットフォームとしての地位は得ているものの、プロセスの公平性を担保する第三者を媒介することなしには、自らの公平性を示すことが難しい状況に陥っている。
無垢な素人 vs 通のどちらが重要なのか?
炎上に強いレビューシステムを構築しているのは、食べログだけではない。コンピュータ・ゲームの流通において、極めて大きな地位を占めているメタクリティークの「メタスコア」も、炎上やバズに対する強い頑健性をもっている。
スコアの算出にあたっては、ゲーム情報を扱う専門サイトのレビューを複数収集し、それらの点数を独自の計算式で算出している。これも、具体的にどのような形で最終的なスコアが算出されているのかは明らかになっていない。
メタスコアは、基本的にプロのゲームライターなどによる評点がベースになっている。そのため、評点は一般のユーザーレビューと比べるとブレにくく、炎上やサクラなどの影響が紛れ込む余地も少ない。とはいえ、メタスコアには、集計の仕方には、独自性はあるものの、こういった商業レビュアーのスコアを用いるというアイデア自体はインターネット以前からあるものだ。そして、こういった「プロ」や「通」による評価に、脆弱性が存在していることも、よく知られている。
端的に言えば、新しいものを評価するのが苦手である。
ゲーム好きから大きな支持を得るようなタイプの作品であれば、当該作品の主要な消費者の満足度とメタスコアは、概ね一致している。100点満点中の、80点代や、90点代の高得点を得ているゲームはだいたいそういったものだ。
しかし、既存のゲームのユーザー層から大きく離れるような層にアピールするゲームは、あまりまともに評価できない。たとえば『ポケモンGO』(2016)のメタスコアは、たったの69点だ。これは、かなり凡庸なゲームに対して与えられるスコアだと言って良い。メタスコア基準で言えば『ポケモンGO』はたいしたゲームではないのだ。
図1はこの傾向を可視化するために、筆者が数年前にデータをとったものだ。GDC Awardsというゲーム業界のなかでも特に国際的な権威のある賞の部門賞を受賞した作品が、それぞれメタスコアを何点ほど取れたのかを調べたものだ。ゲームのサウンドや、CGの良し悪し、技術的なクオリティについてはゲームの賞と、メタスコアの評価は一致しているが、イノベーション部門の得点だけ、統計的に有意な水準で分散が大きい。具体的なタイトルを挙げると、『Wii Sports』(2007)は、76点。『Nintendogs』(2006)が83点といった形でゲーマーらしいゲーマーを狙っていないタイトルだと、あまり点数が振るわない傾向が明確に見て取れる。
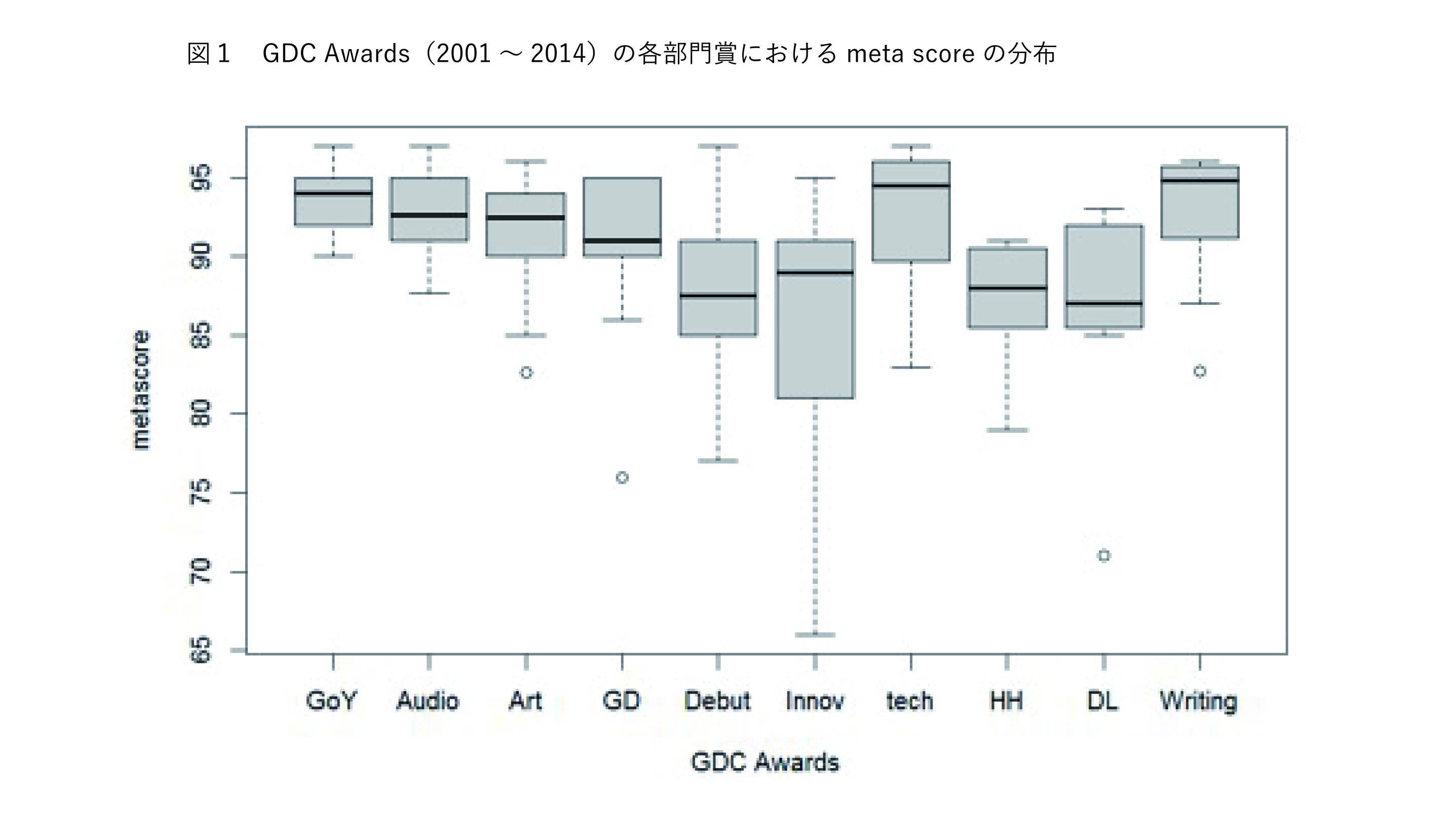
(Inoue(2015), Game reviewers can’t notice innovation,Replaying Japan 2015)
「プロ」や「通」の評価に重み付けをすれば、こういった新規層の評価ができないという現象は当然起こる。
食べログでも似たような現象を目にすることは多い。食べログで評価が高いのは、そのジャンルの「通」の評価が得やすい店の料理であって、味の濃いB級グルメ的な人気店がレビューの投稿数の多さにもかかわらず3.1や、3.0といった点数に留まっている状態を見ることも少なくない。
こういった頑健性をもった情報集約システムを選ぶということは、その頑健性を可能にしている偏りそのものを受け入れるということと繋がっている。
自分自身が当該分野の「通」に属する価値観をもっているという自覚があり、「通」の推薦がほぼ当るという実感をもっているのであれば、こういった情報集約システムを用いることは悪くないかもしれない。しかし、「プロ」や「通」による評価というのは、評価に安定性があるぶん、その代償として、保守化してしまうことと限りなく近い。
安定的であるということは、評価基準の更新を起こすような評価制度の変容メカニズムの作動をよくも悪くも抑えてしまう。
安定的な一つの価値体系を作り上げるということは、一個の文化の形成ということでもある。「これがうまい」「これが面白い」「こういうものこそが美しい」という規定をする体系が成立し、それを一定のコミュニティにおいて共有可能な状況というのは、それ自体に価値があるとも言える。それをわざわざ破壊しなくてもよい。
しかしながら、安定的な評価システムを構築することが、評価の変容を抑えるということは、イノベーションを活性化させるという観点から言えば、イノベーションの阻害要因となる悪しき一元的な保守化でもある。
一元的な価値を安定的に表現することは、意味がないわけではない。しかし、それは、多様な価値体系や、新しい価値体系へのアクセスを悪くしてしまう。
偶然性 vs 効率性
では、新しい価値体系や、多様な価値体系へのアクセスを可能にするアルゴリズムは何かあるのだろうか? 価値観を一元化する圧力から自由でいて、かつ安定した情報集約の仕組みというのはありうるのだろうか?
これについては、さまざまな試行錯誤はあるものの、良い解答があるわけではない。単なる人気ランキングが結果的に多元的な価値が同時的にあらわれる場になっていることもよくあるし、新しいものを発見するという意味では、ランダムに近い情報提示の仕組みのほうが、むしろ優秀だとういうこともありうる。たとえば、乱雑に本が重ねられた古本屋でたまたま手にとった本が良かった、というようなことがある。
古本屋の実店舗は、一応「本になっている」という形式によって情報自体の最低限の質の保証はされており、その上で本の選定が、雑に成り立っている。かなりしっかりとした学術書が100円で売られていることもあるし、安かったからという理由だけで買った本が意外によかったというような偶然で本の並びが変わる。「たまたま売れ残っていた」「たまたま大学の先生が近くに住んでいる古本屋だった」とか、そういう理由で古本屋の品揃えは変わったりする。人気順に並び替えられているわけではなく、地理的・時間的な偶然性によって並び替えられている。古本屋に並べられている本はもちろん「古い」本なのだが、本を読む人との関係性をコントロールする仕組みは、良くも悪くもあまり制御されていない。とりわけ、ネット経由で本を見つけやすい今と比べると、ネット以前は、古本屋で良いと思える本と出会うというイベント自体が、一期一会の機会を逃してはいけないという感覚が発生しうる特別な偶然の支配するものだった。それゆえ、「たまたま出会った本」の価値が今よりもずっと高かったという側面がある。
もっとも、言うまでもなく、これはインターネット以前からの仕組みである。もちろん、情報探索の効率性という観点から言えば、2021年現在としては褒められたものではない。探したい本が比較的はっきりとしているのならば、古本屋を何十件もめぐるよりも、ネットで検索をして取り寄せるなり、該当の本を所蔵している近くの図書館を探して行ったほうが良いことのほうが大半だろう。歴史研究者が参照するような古典籍ですら、近年はインターネットでの公開アーカイブにしていく活動が進んでいる。
何かを検索しようとする意思と、ちょっとしたテクニックさえあれば、インターネットの便利さは、年々、増している。しかし、「何を検索すればいいのか」ということのきっかけを与えることは容易ではない。インターネットは近場の情報同士を結びつけることはできても、関連性の遠いところにある情報の面白さに気付かせる機能は、実空間と比べてもあまり高くない可能性がある。
もっとも、近年のインターネット言論の二極化をめぐる研究を参照すると、オフラインでの人間関係や、情報摂取のあり方のほうが、下手をするとオンライン空間よりもマズいのではないかという議論もある。懐古主義な楽園論が簡単に成立するとは思えないが、二〇世紀的な知識獲得のプロセスは明らかに今とは違っていた。
それは、インターネットの弊害を克服するものだとは思えないが、「偶然性」は、現在のインターネットにとってのアキレス腱の一つである、ということぐらいは言えるだろう。
どこまで理解し、どのような価値を選ぶのか

以上、「レビュー」のありようについて概観してきた。表2に概ねの議論をまとめておく。
現状のレビュー的な情報集約システムについて、その脆弱性や癖の強さについて、利用者の多くが理解していない。その意味では、amazonレビューにせよ、食べログにせよ、メタスコアにせよ「誤解に基づいた数値の流通」は歓迎できたものではない。挙げた中では、とくにamazonレビューのような素朴なシステムの無意味さは、ほとんど解説の必要すらなくなりつつある。だが、そのことが逆説的にamazonレビューに大きな意味があるかのような「誤解」を少なくしているのは歓迎すべき事態だとも言えるだろう。
一方で、食べログや、メタスコアなどのような「通」の価値を基盤とする、ブラックボックスの多いスコアリングの仕組みは、話がややこしい。学者がよく気にする被引用文献数に基づいたh-indexなどの指標もそうなのだが、結局のところそのスコアがどのような挙動を見せるのかということについて、知らないまま運用されるべきものではない。食べログのスコアは、高得点かどうかは比較的意味のある情報だが、低得点かどうかというのはあまり意味がない(単に高得点をつける根拠が足りていないだけであることが多い)。メタスコアは、ゲーマー受けしそうな作品が、実際に(特に欧米の)ゲーマー受けしているかどうかを知る指標としてはある程度有用な指標だが、新規性の強いタイトルの評価にはほとんど使えない。
こういったスコアの特性は、それぞれのスコアを使い込んでいれば、体感的にわかってくるようなことではある。しかし、スコアを出している事業者がそこまで積極的に宣伝するような話でもないし、客観指標めいたものに過剰な価値を見出す人は後をたたないので、数値が過剰な意味を読み込まれてしまう。
スコアに過剰な意味を読み込むのではなく、どのような価値を重視するのか、ということから、スコアを選ぶ必要がある。
キャラクターとしてのシステム
私は、ゲーム研究者を名乗っているので、ゲームのことを少しぐらいは知っているつもりだが、メタスコアのゲーム評価と私の好みとは、そこまで合致しない。そのことを、だいぶ昔からよく自覚している。
メタスコアのことは、いかにもゲーマーらしいゲーマーの友人(アメリカ人)のようなものだと思っている。いかにもゲーマーらしい友人が、アーティスティックなゲームだとか、新機軸のゲームに対して、「うーん、まあいいとは思うけど、俺はちょっと……」みたいな反応を見せることはよくある。それとほとんど、変わらないと思っている。ある意味では、信頼ができるし、「ああ、あいつだったら、こう言うだろうな」というのが、そこそこ正確に予測できる自信があるし、だいたい当たる。「あの野郎、俺のイチオシの『スクリブルノーツ』に80点以下をつけやがって……」みたいな、軽い恨み言もあるにはある。よくも悪くも、そういうものだと思っているし、そういうヤツだと思っている。趣味が合わないところがあるとは言っても、まあ、6割~7割ぐらいは意見が一致するし、まあ、人間の趣味の一致度合いなんていうのはせいぜい、その程度だと思っていれば、特に腹が立つような話ではない。
多くの人の意見を集約したシステムというのは、何かしらのアルゴリズムで一元化してしまえば、そういった癖のある人間とさほど変わらないような振る舞いを見せる。そのスコアと付き合いが長くなればなるほどに、そこらへんの塩梅は、わかってくる。
多数の人の意見を、集約することによって、データに権威性や、正統性を見出したがる人は多い。サンプリングの手法が適切であり、サンプリングされたものの分布がよく知られた分布に従うことが統計的な検定によって明らかで、サンプリングされた母標本の集団が想定する母集団が「我々」の社会そのものを代表するのだ………という理屈が成立するケースであれば、話はまだわかる。
実際に我々が扱えるデータの多くは、そうではない。癖のあるサンプルを、限界のあるアルゴリズムで、集約したものだ。それは、ある意味では、非常に有用で、何らかの意味での効率性に資することは大いにある。しかし、権威や正統性の源泉とするには、あまりにも脆弱なものだ。
我々は何か賢しらなシステムについて語ろうと思うと、どうしても分析的なモードで語りがちになるが、実際のところ多くの賢しらなシステムは、人間のような泥臭さがある。
マイクロソフトのAI「りんな」は、名前の付いたキャラクターとして運用されているが、大多数の情報集約のシステムにも、人間臭い名前をつけたほうが良いのかもしれない。(終)
井上明人(Inoue Akito)
ゲーム研究者。現在、立命館大学講師。慶應義塾大学政策・メディア研究科修士課程修了後、国際大学GLOCOM助教、関西大学特任准教授などを経て現職。ゲームという経験が何なのかを論じる『中心をもたない、現象としてのゲームについて』を連載中。また、ゲームのアーカイブやデータベースに関わるプロジェクトに関わっている。単著に『ゲーミフィケーション』(NHK出版,2012)。開発したゲームとしては、震災時にリリースした節電ゲーム『#denkimeter』(CEDEC AWARD ゲームデザイン部門優秀賞受賞)、の他に『ビジュアルノベル版 Wikipedia 地方病(日本住血吸虫症)』など。
自身のサイト「ビデオゲームをめぐる問いと思索」




